Managing files stored in the Bigstep DataLake service using the WebHDFS API and curl¶
This document details how to connect to a DataLake and manage files using the WebHDFS REST API.
Obtaining the kerberos ticket¶
See Authenticating to the Datalake for more details.
Run kinit and use your Bigstep login password when prompted:
$ kinit [email protected]
Password for [email protected]:
You can use klist to see a list of currently active Kerberos tickets.
If you get an authentication error after running any of the file management commands below, that means that your ticket has expired and you need to run kinit again.
Once authenticated, you can use the WebHDFS REST API to issue commands to the DataLake. This is done by sending HTTP requests using curl.
In order to authenticate through Kerberos when running WebHDFS commands, you have to include the –negotiate -u: options when using curl. To include the HTTP headers in the output, use the -i option.
Finding the endpoint URL¶
You can find the address to which the requests must be sent in the Credentials tab of the DataLake.
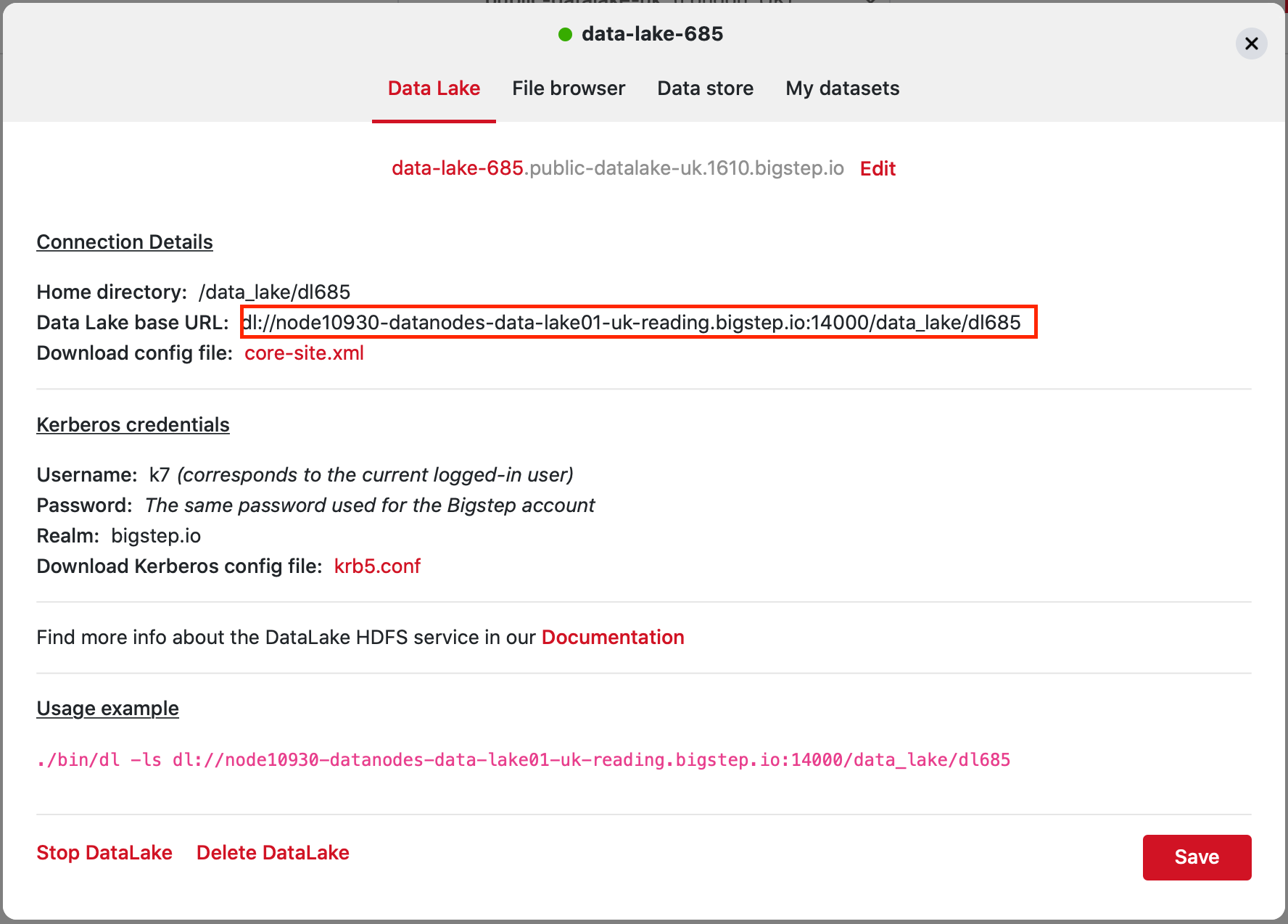
Replace the dl:// prefix with https:// .
Listing directory contents¶
$ curl --negotiate -u: "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY?op=LISTSTATUS"
Copying a file to the DataLake¶
$ curl --negotiate -u: -i -H "Content-Type:application/octet-stream" -X PUT -T "/root/test/example.txt" "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt?op=CREATE&data=true"
The /root/test/example.txt file is copied to the specified location on your DataLake /dlYYY/example.txt
.
The &data=true option has been added to let HDFS know that data is coming through. This means that the HTTP request’s header must also specify the MIME content type -H "Content-Type:application/octet-stream".
If the operation is successful, the client receives a 201 Created response with zero content length and the WebHDFS URI of the file in the Location header:
HTTP/1.1 201 Created
Location: webhdfs://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt
Content-Length: 0
Appending data to a file¶
Let’s say you want to add the contents of example2.txt to the file already existing on the DataLake:
$ curl --negotiate -u: -i -H "Content-Type:application/octet-stream" -X POST -T "/root/example2.txt" "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt?op=APPEND&data=true"
As HDFS does not support random reads and writes, this is the only way to edit the data in a file, apart from deletion.
Reading data from a file¶
$ curl --negotiate -u: -i "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt?op=OPEN"
If you want to copy the data in a file on the DataLake to a file on the instance (newfile.txt), you can simply use a I/O redirection:
$ curl --negotiate -u: "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt?op=OPEN" > "newfile.txt"
Deleting a file¶
$ curl -i --negotiate -u: -X DELETE "https://node10930-datanodes-data-lake01-uk-reading.bigstep.io:14000/webhdfs/v1/data_lake/dlYYY/example.txt?op=DELETE"
Additional resources¶
- WebHDFS HTTP GET operations for additional information.
- PHP client
- Java WebHDFS client
- Ruby WebHDFS client