Glossary¶
Whats an Infrastructure?
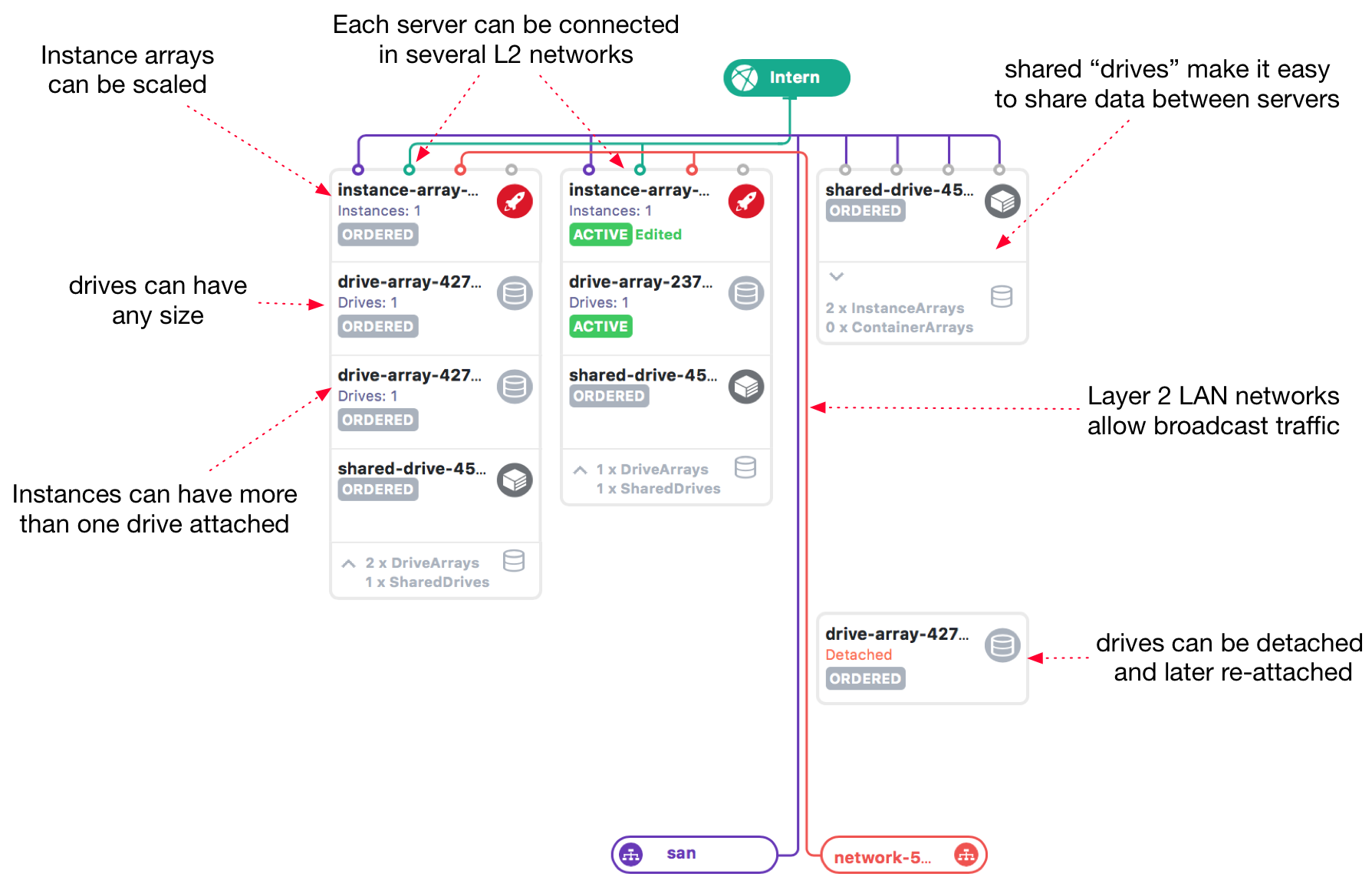
An infrastructure is a distinct system architecture configured by a user. It contains various other elements, such as Instance Arrays and Drive Arrays, as well as the connections between them. The infrastructure acts like a virtual datacenter and private networks can be configured to link the servers in its composition. It can communicate with servers from other infrastructures only through public IP addresses.From a security perspective, infrastructures are equivalent to an AWS VPC.
Infrastructures have two stages: the planning/design stage and the deploy one. Hardware resources are allocated in the planning stage but the changes have to be deployed before they become available.A user can have more than one infrastructure;the default limit is 10 at Bigstepbut it can be increased if needed.
A typical user infrastructure architecture would look similar to this:
Whats an Instance?
The actual metal cloud servers are known as instances. They can be managed just like physical machines and operations such as power on, power off or reset are available either directly from the interface or through IPMI commands.
Metal Cloud instances are designed to be started and stopped as quickly as possible, so their configuration is persistent even when they are offline. As soon as an instance is started, its drives, network interfaces and assigned IP addresses become active again.
Instancesare logical-level concepts. Behind each Instance there is aServerbut which particular one is of no importance to the user. The server can be swapped with another while the Instances properties such as access credentials, DNS records etc are preserved.
The mapping between an instance and a server is done at provisioning time and is created when the user requests a compute resource. An instance can be mapped to another server if the user needs more resources or needs a replacement.
Whats an Instance Array?
An Instance Array is a group of Instances that should serve the same purpose or share the same workload. They provide excellent scalability with minimal costs, since they can be resized at any time by adding or removing servers. Instance Arrays can include different servers but using a single server type is recommended.
All instances that are part of an Array share a default configuration that can be tweaked for the entire group. For example, the instances share a DNS record that points to the public IPs of all instances inside it. In addition, any network connected to the Array will be available for all instances.
Whats a Drive?
A drive is a disk that can be attached to an instance. While some types of servers have local storage available, Drives are accessed through the SAN network and mounted using iSCSI. Operating system templates can be copied on Drives in order to setup new servers as fast as possible. It is also possible to expand drive capacity at any time, but they cannot be downsized.
A Drive can be detached from an instance and attached to another one, which allows scaling resources with minimum downtime. For example, you can delete an existing instance and then provision a more powerful one and attach the initial Drive to it.
Whats a Drive Array?
Drive Arrays represent a group of Drives that can be resized dynamically. When a Drive Array is attached to an Instance Array, every Instance will be automatically connected to a Drive. As the Instance Array is scaled, the Drive Array is also resized by adding or deleting Drives to match the number of Instances. All of the Drives that are part of an Array have the same size by default, as well as the same operating system template, but they can be customized individually.
Whats a Shared Drive?
A Shared Drive is a special type of storage device that can be attached to multiple Storage Arrays at the same time, through the SAN network. Shared Drives have many practical applications and are a further scalability option for multi-server architectures. The same block device is exposed to multiple servers, but a distributed file system must be installed on top of it, for example the vmfs file system used by VMware ESXi.
Whats a Data Lake?
A data lake is a special file system compatible with the Apache Hadoop framework that is designed for scalability and large volumes of data. To achieve high horizontal scalability, the DataLake service employs a distributed replication schema. The system attempts to distribute the blocks evenly across the data-nodes while also making sure replicas are not on the same machines or disks.
Every node has many disks, managed independently, and this replication system ensures that disk failures are not catastrophic. As a result, the Data Lake provides a very safe and cost-effective storage option for modern Big Data applications. Customers are only billed for the actual volume of data stored and can access the Data Lake either through a command line tool or using client libraries.
Whats a Subnet?
A Subnet is a range of IP addresses, minus the first and last addresses (gateway and broadcast, respectively). Subnets are added to networks and then IP addresses are associated automatically with instance interfaces (which correspond to server interfaces).